
This short post is about "Prompt Engineering" for ChatGPT, the thing that is being overhyped a lot recently. How to drastically improve the quality of responses, as well as your understanding of the structure of prompts for certain tasks. Let's break it down.
Simple prompts
The basic and most common way to communicate with ChatGPT. Initial single-word prompts allow the chat to recognize and classify objects that were not previously mentioned in the dialog. Most often used to obtain exact data, or as an starter for a more complex group of prompts. Let's try a simple prompt like "write introduction to Canva":
We get a simple response without reference to any particular context. That's the way how many users communicate with ChatGPT.
Advanced prompts
So, here we give ChatGPT an example of a structure that we would like to get in response. Chat tries to "predict" based on the given structure and parameters. For example, for an overview of the same Canva, I googled a bit for the main characteristics (what is it, how much etc.) to compare the software:
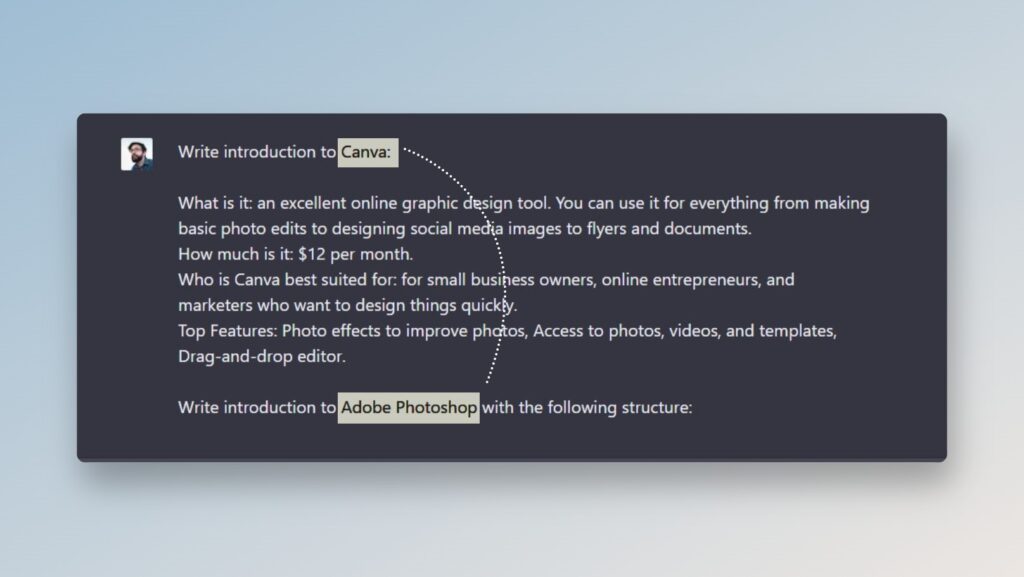
And ask to do the same for Adobe Photoshop with one simple prompt. Let's see the result:
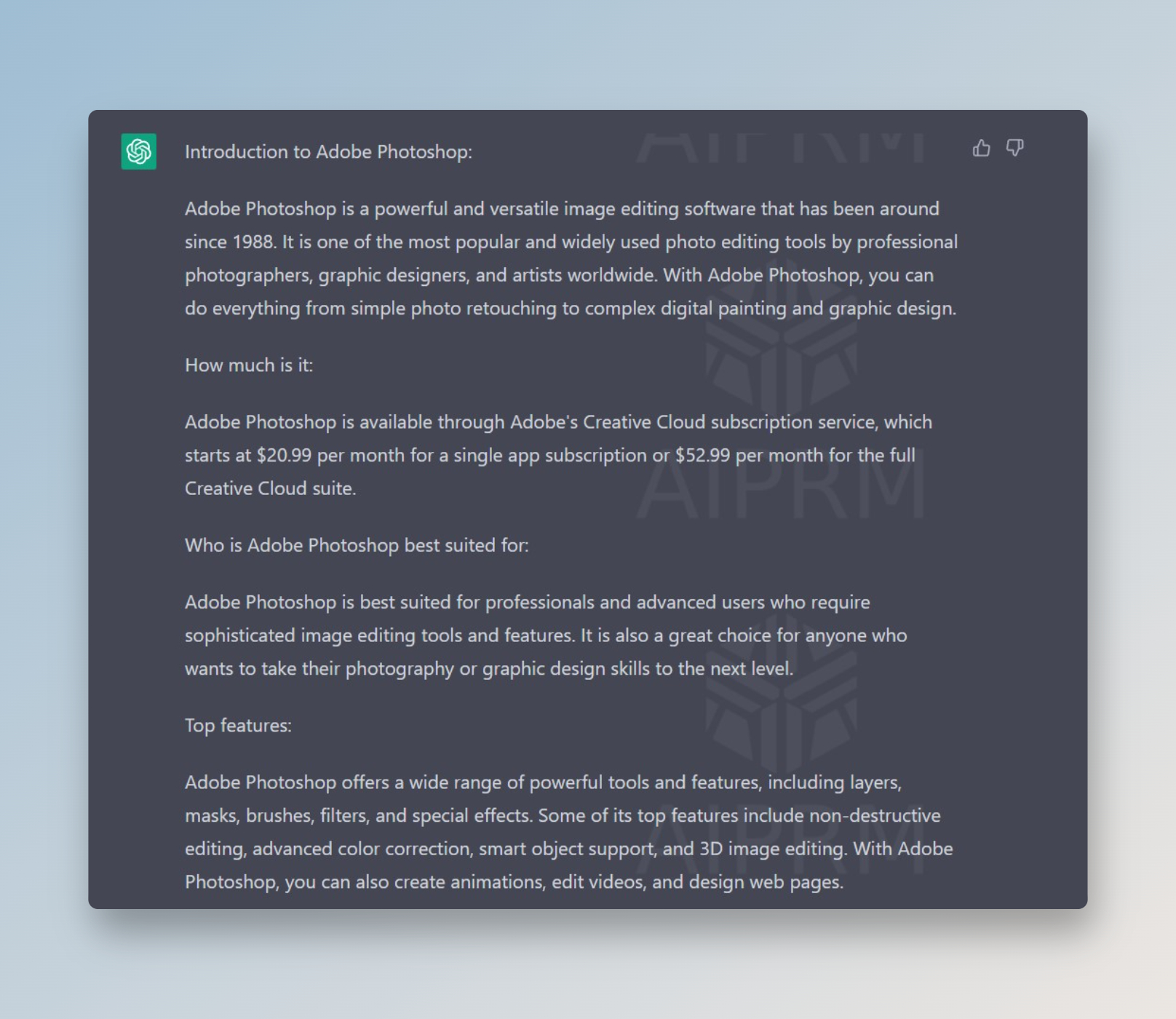
You can go on substituting names of other software as much as you like. This is a typical example of how one simple prompt can create an infinite number of product comparisons or services.
Also, we don't need to copy the first prompt with the characteristics completely. The chat remembers the structure and works with it further. Let's try to add Wepik instead of Photoshop. Once again with just one line request - "Write introduction to Wepik following above structure:"
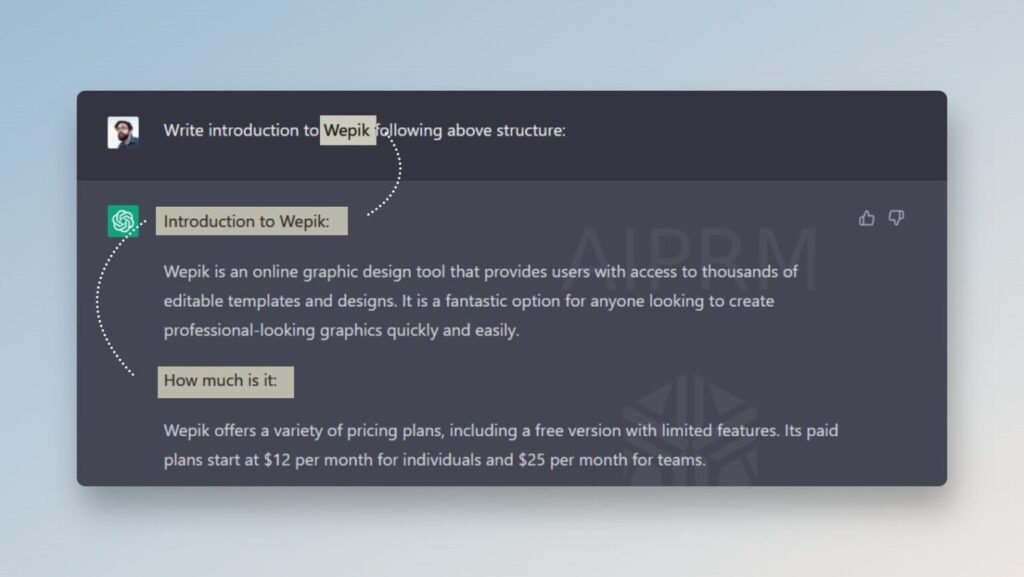
That is, in this way we can easily "train" the model within a single dialog, without inserting huge chunks of text over and over again, but by setting the right parameters for comparison.
A Competition with pSEO
Programmatic SEO (aka pSEO) is an approach to creating a lot of pages on a database with a well-defined structure. You can try it even without knowledge of coding, for example through https://pagefactory.app. It usually looks like this:
Let's try to make a small database for a similar approach to ChatGPT. By the way, collecting and classifying data usually takes longer than actually generating responses through the API.
So, let these be the same, like offroad bikes (guess called them right). Let's make a basic table of 2-3 models (googled this site https://motorcyclesspecs.com/yamaha-tt-r230/ to pick up a couple of specs and features:
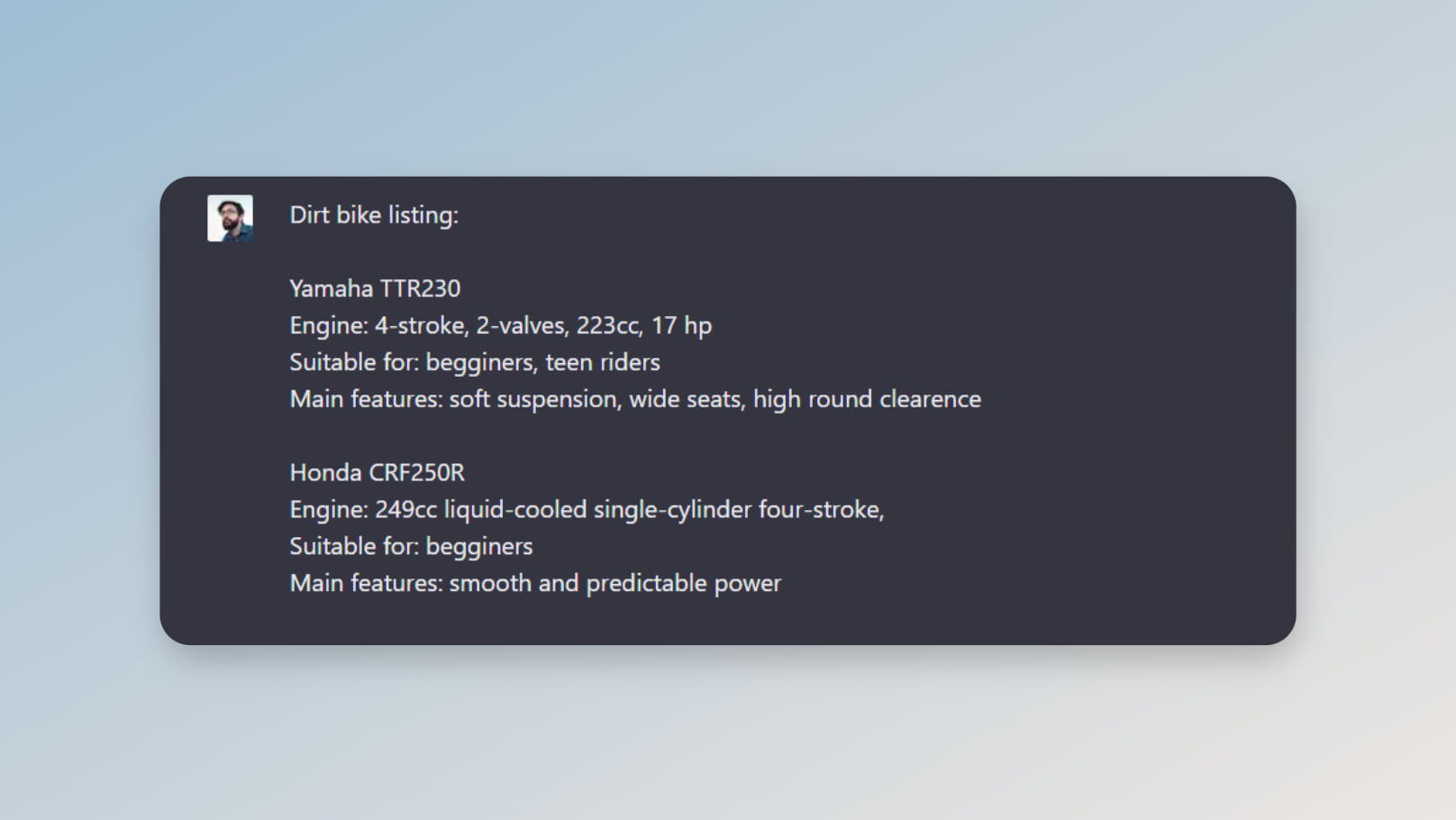
Just take two random models and determine the main specs/features for comparison. I took Engine, Suitable for and Main Features. And just like that give it to ChatGPT. And we get an answer with a small text block for a listing:
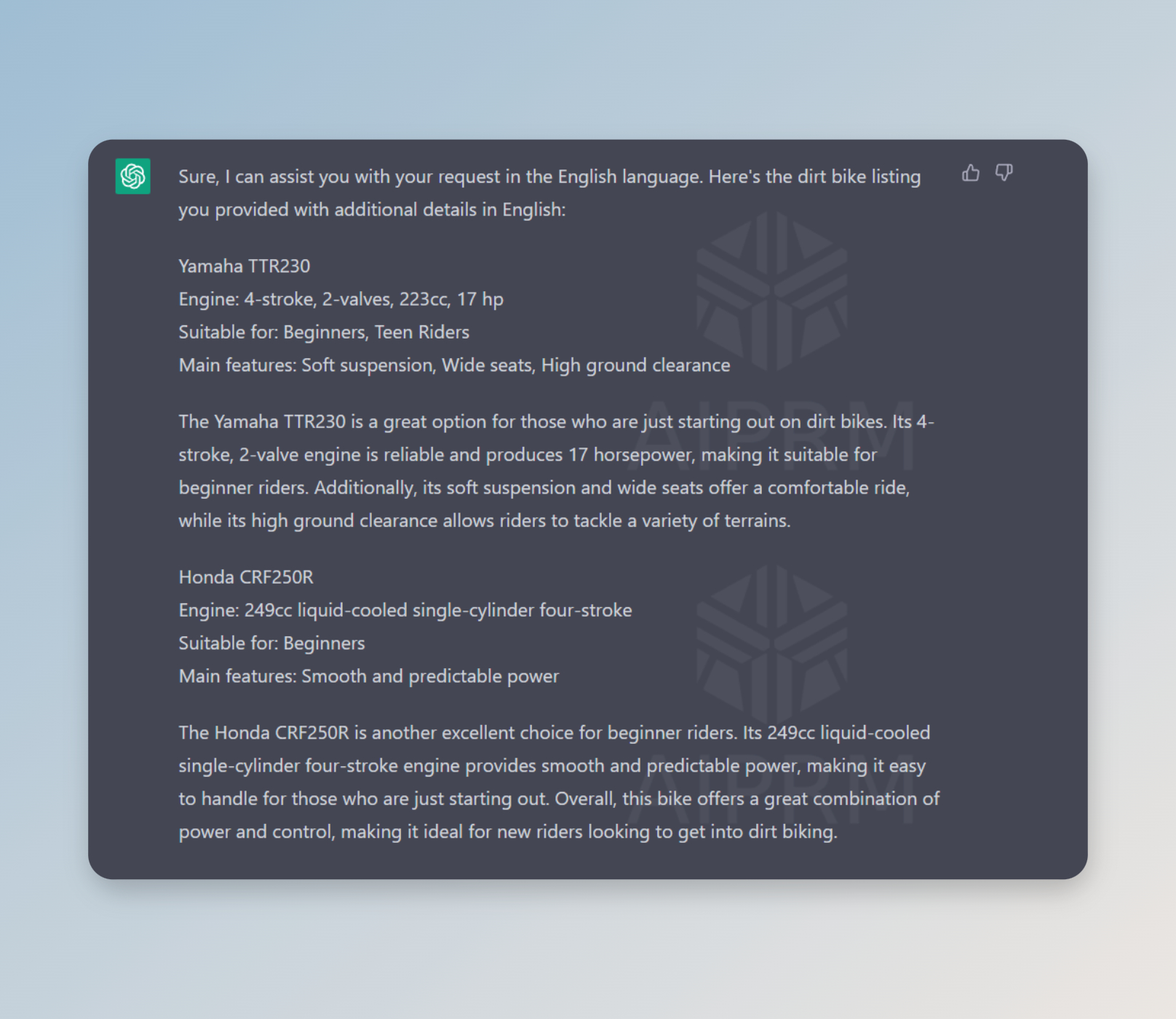
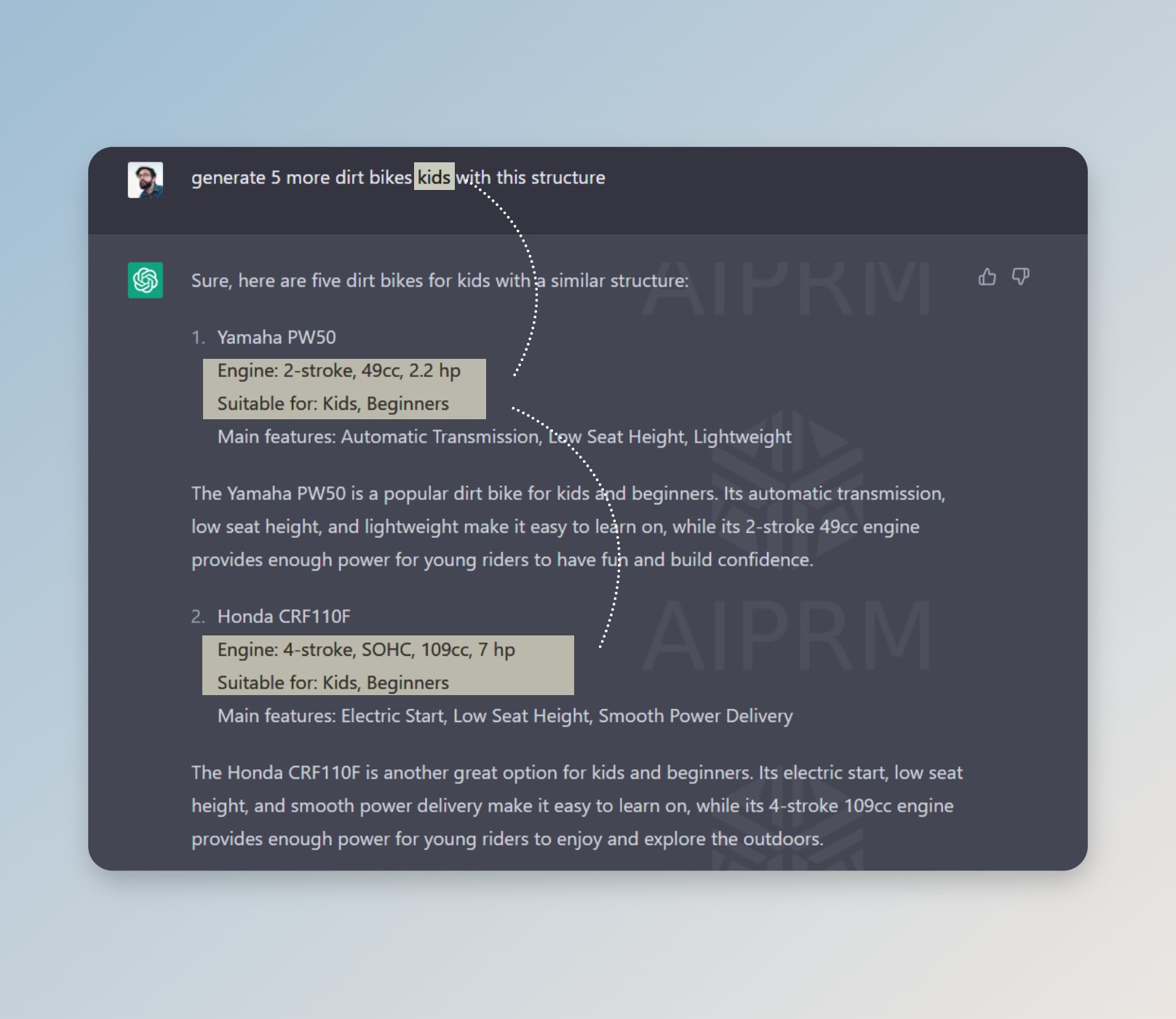
Then a simple prompt asks for 5, 10, 15…as many more as you like to see the *magic:

I mean, you get it, right? We have an unlimited number of databases on any topic with almost instant sorting by any parameters. How about selecting motorcycles by specific group? For example the best ones for kids? Again, with a single request.
And ask to sort the output in a table like this: make a table for dirt bikes with suitable for and main features column. Here we go:

Free access to thousands of databases, on thousands of topics, with almost instantaneous processing of prompts. A very cool time-saver for repetitive and typical queries, because we always get predicted results in return.
Another example of model training
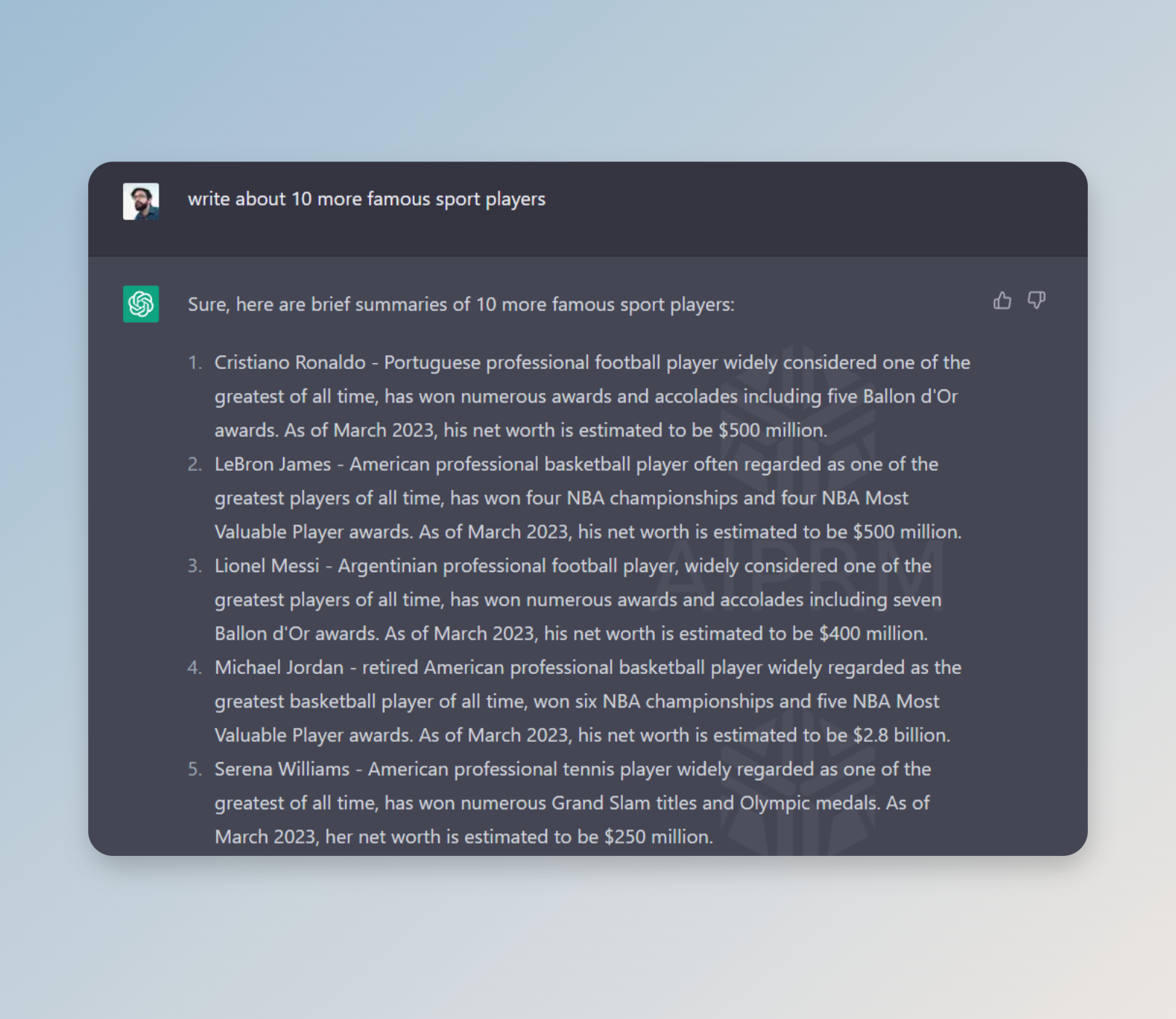
Somehow I came across a large website - https://wealthygorilla.com (2.5M according to SimilarWeb). Let's try to repeat the same in ChatGPT. We take the introduction, which has a similar structure for almost all pages and copies a couple of paragraphs. Substitute with square [quotation marks] where to replace data. Send it to the ChatGPT:

And with the next prompt ask to write about a dozen more athletes. To get a completely similar sentence structure it is necessary to experiment a little more with queries to get a more detailed answer. But, what I want to show here is how you can get the desired result by simply training a model on a given topic in a couple of prompts. Bottom line:
Be on the smart side. Cheers!